Thoughts on the S3 outage
It’s in the news. Amazon S3, the popular object store crashed yesterday in one of their regions and affected multiple other sites, including Slack and GitHub.
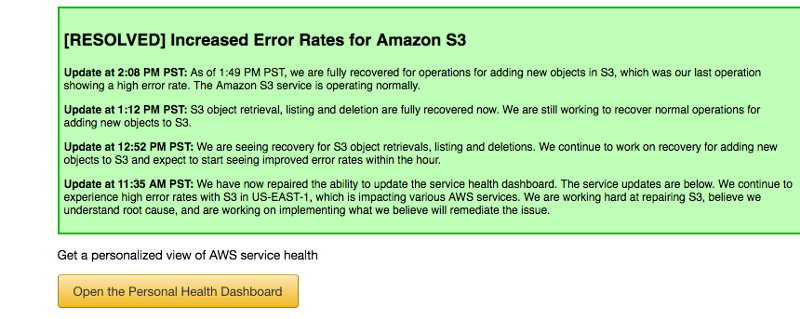
So here are some comments about it:
-
AFAICT the s3 outage was in us-east-1 region. Other regions didn’t have S3 affected.
 S3 in Europe* This is not the first s3 outage.
You may have read about what this affects the 11 nines promise. Most likely, it doesn’t . The promise is for durability (if you write, no errors reading), not availability. For availability. The SLA is much lower.
S3 in Europe* This is not the first s3 outage.
You may have read about what this affects the 11 nines promise. Most likely, it doesn’t . The promise is for durability (if you write, no errors reading), not availability. For availability. The SLA is much lower.
 SLA is 4 nines.https://aws.amazon.com/s3/faqs
SLA is 4 nines.https://aws.amazon.com/s3/faqs -
For quite some time, the status page in Amazon wasn’t working, affected by their own outage. At some point you could see all green page and only a text at the beginning indicating the outage. Similarly dashboards in many regions wouldn’t work. This is more serious than the outage itself.
-
If your application is mission critical and cannot afford 3 hours of outage, prepare for it. Go multi region or even multi provider. There are cloud architects designing “high available applications” using three availability zones in a single region. BTW, anything beyond two AZ is flushing money down the toilet.
-
If your contingency plan doesn’t allow to deploy without Github, coordinate without Slack, you need to replan.
-
Many people are suggesting this goes against cloud or serverless. I think this is the very reason you should consider cloud and serverless. Managing systems at scale is quite difficult. Leave it to people who know about it (Amazon or other providers)
Final note. I’m super excited about what we will learn from their postmortem.
Edit: The postmortem came out. Less interesting than I had thought.
First published here